「Deep Learning」を理解する

オリジナルサポートサイト
「Pythonで学ぶディープラーニングの理論と実装」
この本は「深層学習」の要点をわかりやすく解説してあります。
プログラミングをして理解する方にはお勧めの本です。
理論の理解、開発環境構築、プログラミングを実装しディープラーニングを理解してみます。
「深層学習」の理論

ニューラルネットワークの「学習」とは
学習
訓練データから最適な重みパラメータの値を自動で獲得すること
学習が行えるように「損失関数」を基準としその値が最も小さくなる重みパラメータを探し出すことが学習の目的
「活性化関数」
入力信号の総和を出力信号に変換する関数を活性化関数(activation function)と呼ぶ
「損失関数」
p, qが離散確率変数なら、これは次のようになる。
「活性化関数」
入力信号の総和を出力信号に変換する関数を活性化関数(activation function)と呼ぶ
- シグモイド関数
- ReLU (Rectified Linear Unit)
「損失関数」
p, qが離散確率変数なら、これは次のようになる。

勾配・勾配法
勾配:
すべての偏微分をベクトルとしてまとめたものを勾配(gradient)という。
勾配は各地点において低くなる方向を指します。言い換えると勾配は各場所において関数の値を最も減らす方向です。
勾配法:
機械学習の問題の多くは学習の際に最適なパラメータを探索する。
ニューラルネットワークも同様に最適なパラメータ(重みとバイアス)を学習時に見つける必要がある。最適なパラメータとは損失関数が最小値をとるときであり最小の場所を探すのに勾配法を使用する。
勾配法は現在の場所から一定の距離だけ進み繰り返し勾配方向に移動し関数の値を徐々に減らすのが勾配法(gradient method)という。
ステップ1 ミニバッチ
訓練データからランダムに一部のデータを選び出す。そのミニバッチの損失関数を減らすことが目的
ステップ2 勾配の算出
各重みパラメータの勾配を求める。損失関数の値を最も減らす方向を示す。
ステップ3 パラメータの更新
重みパラメータを勾配方向に微少量更新する。
ステップ4 (繰り返し)
ステップ1、ステップ2、ステップ3を繰り返す。
学習の回数が進むにつれて損失関数の値が減り最適なパラメータへと徐々に近づくことが理想
#ニューラルネットワークの学習は上の手順にようる方法で行う。 使用するデータはミニバッチとして無作為に選ばれたデータを使用 確率的勾配法(SGD)と呼ぶ。 確率的とは「確率的に無作為に選び出した」という意味。
#ディープラーニングの学習(トレーニング)は関数のパラメータの値、適切な重みをもとめること。推測とは学習で求めた重みを用いて入力層のデータから出力層の値を算出すること。
学習において重要なテーマ
- 最適な重みパラメータを探索する最適化手法
- 重みパラメータの初期化
- ハイパーパラメータの設定
- 過学習の対応(Dropout) などの正則化手法
- Batch Normalization手法
パラメータの更新
- SGD:確率的勾配降下法(SGD: stochastic gradient descent)
- Momentum:モーメンタム物理法則に準じる動き
- AdaGrad 学習係数の減衰(learning rate decay)
- Adam パラメータの要素ごとに適応的に更新ステップを調整
重みの初期化
- 重みの初期値としてどのような値を設定するかでニューラルネットワークの学習の成否が分かれる。
- Xavierの初期値 一般的なディープラーニングのフレームワークで標準的に用いられている。
- 活性化関数にsigmoid, tanh のS字カーブのときはXavierの初期値を使用しReLUを使用する場合はHeの初期値を使用する。
誤差逆伝搬法:重みパラメータの勾配の計算を効率よく行う手法


- 連鎖率:逆方向の伝搬では「局所的な微分」を順方向とは逆方向(右から左へ)伝達していきます。「局所的な微分」を伝達する原理は連鎖率(chain rule)によるものである。
- レイヤ(層):活性化関数 ReLU(Rectified Linear Unit), Sigmoid
- 順伝播で行う行列の内積は幾何学の分野では「Affine (アフィン変換)と呼ぶ その変換処理は「Affineレイヤ」
- 出力層:ソフトマックス関数は入力された値を正規化して出力します。Softmaxレイヤは入力された値を正規化 出力の和が1になるように変形して出力 手書き数字認識は10クラス分類を行うためSoftmaxレイヤへの入力は10個ある。
過学習:過学習が起きる原因として
- パラメータを大量に持ち、表現力の高いモデルである
- 訓練データが少ない
Dropout
Dropoutはニューロンをランダムに消去しながら学習する手法。訓練時に隠れ層のニューロンをランダムに選び出し選び出したニューロンを消去する。
Batch Normalization
各層でのアクティベーションの分布を適度な広がりを持つように調整をする。
データ分布の正規化を行うレイヤをニューラルネットワークに挿入する。 ミニバッチごとに正規化(データの分布が平均が0で分散が1)を行う。
- 学習を早く進行させることが可能
- 初期値に依存しない
- 過学習を抑制する
エポック(epoch)とは単位を表します。1エポックとは学習において訓練データをすべて使い切った時の回数に対応
例:10,000個の訓練データに対して100個のミニバッチで学習する場合、確率的勾配降下法を100回繰り返したらすべての訓練データを見たことになります。 この場合1エポック=100回となります。OrderDictは順番付きのディクショナリです。 「順番付き」とは追加した要素の順番を覚えることができる。
全結合ニューラルネットワーク(Fully-Connected NN)は最も基本的なニューラルネットワークで全結合とも呼ばれている。
畳みこみニューラルネットワーク
- 畳み込みニューラルネットワーク(convolution neural network: CNN) は画像認識や音声認識で使用。
- 新たに「畳み込み層:Convolutionレイヤ」と「ブーリング層:Pooling」を追加。 CNNでは畳み込みの入出力データを特徴マップ(feature map)という場合がある。
- 畳みこみ層: 「パディング」、「ストライド」、データは形状のあるデータになる。「パディング」 畳み込み層の処理を行う前に入力データの周囲に固定のデータを埋めること。 「ストライド」 適用する位置の間隔をストライドという。ストライドを2とするとフィルターを適用する窓の間隔が2要素ごとになる。
- 全結合層の問題点はデータの形状が”無視”されてしまう。 一方畳み込み層では形状を維持。画像はデータを3次元データとして受け取り3次元のデータとして出力する。
- 畳み込み演算は画像処理での「フィルター演算」に相当。 3次元データの畳み込み演算は縦・横方向に加えて奥行方向(チャネル方向)に特徴マップが増える。3次元畳み込み演算で注意する点は入力データとフィルターのチャネル数は同じ値にすること
- ブーリング層 ブーリングは縦・横方向の空間サイズを小さくする演算
- 学習するパラメータがない 対象領域から最大値をとる(もしくは平均)の処理なので学習すべきパラメータは存在しない。
- チャネル数は変化しない 入力データと出力データのチャネル数は変化しません。
- CNNでは各層を流れるデータは4次元のデータ。 データの形状が(10,1,28,28) 高さ28、横幅28で1チャンネルのデータが10個
- im2col(input_data, filter_h, filter_w, stride=1, pad=0)
- input_data データ数、チャネル数、高さ、横幅
- filter_h フィルターの高さ
- filter_w フィルターの横
- stride ストライド
- pad パディング
- 代表的なCNN
- LeNet
- AlexNet
ディープラーニングの歴史と様々なCNN
- ImageNet 100万枚を超える画像のデータセット
- VGG 畳み込み層とブーリング層から構成される基本的なCNN 重みのある層(畳み込み層や全結合層)を全部で16層もしくは19層まで重ねているのが特徴(VGG16, VGG19)
- GoogLeNet ネットワークが縦の方向だけでなく横方向にも深さ(広がり)を持っている。 インセプション構造と呼ばれる。
- ResNet これまで以上に層を深くできるような仕掛けがある。
- 分散学習 ディープラーニングの学習をスケールアウトするには複数のGPUや複数台のマシン(Intel(R)Xeon, Intel(R)Xeon Phi)で分散して計算を行う必要がある。 フレームワークとしてGoogle TensorFlow, Microsoft CNTK(Computational Network Toolkit) は分散学習を重要視して開発が行われている。
- 実用例 物体検出、セグメンテーション(画像に対してピクセルレベルで暮らす分類を行う問題) 画像キャプション(画像を与えると説明する文書を自動生成する) 画像スタイル変換(アーティストのような絵を”描かせる”)自動運転、強化学習(Deep Q-Network)
開発環境
- CentOS 7 (7.3.1611) x86-64
- Atom インストール
- Text Editor
- Download .rpm
- yum install atom.x86_64.rpm
- Python インストール
- Python 3.5 version 64-BIT installer
- NumpPy
- Matplotlib
- Terminal bash Anaconda3-4.2.0-Linux-x86_64.sh
- /root/anaconda3
- /home/working
- python --version
- Python 3.5.2 :: Anaconda 4.2.0 (64-bit)
- [root@localhost working]# python
- Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 2 2016, 17:53:06)
- [GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux
- Type "help", "copyright", "credits" or "license" for more information.
- 参考資料
- deep-learning-from-scratch
- git clone https://github.com/oreilly-japan/deep-learning-from-scratch.git
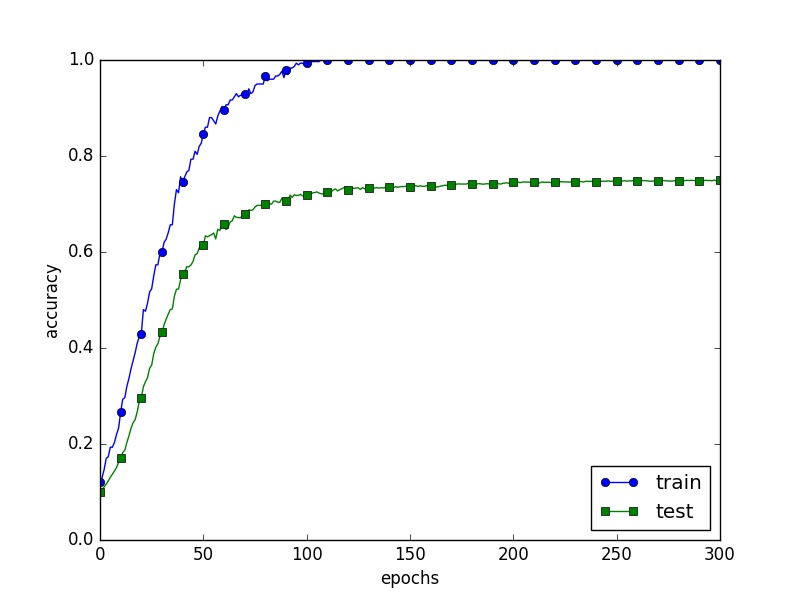
学習アルゴリズムの実装(訓練データとテストデータに対する認識精度の推移)
<memo>
neuralnetwork:train_neuralnet.py,two_layer_net.py
<memo>
neuralnetwork:train_neuralnet.py,two_layer_net.py
common:functions.py,gradient.py

誤差逆伝播法(back_propagation)に対応したニューラルネットワークの実装
レイヤーという単位で実装 各レイヤーにはforward, backwardというメソッドを実装しデータを順方向と逆方向に伝播することで重みパラメータの勾配を効率的に求める。
誤差逆伝播法で勾配を求める
<memo>
back_propagation: train_neuralnet.py, two_layer_net.py
common: layers.py, util.py
- ニューラルネットワークの順伝播で行う行列の内積は幾何学の分野では「アフィン変換」と呼ぶAffine レイヤを実装
- 活性化関数として使われるReLU(Rectified Linear Unit)を実装 順伝播時の入力が0より大きければ上流の値をそのまま下流に流します。逆に順伝搬時に0以下であれば逆伝搬では下流への信号は止まる
- 出力層はsoftmax-with-Lossを実装 softmaxは入力された値を正規化して出力する。 損失関数である交差交差エントロピー誤差(cross entropy error)を含めてsoftmax-with loss レイヤとして実装する。
学習に関するテクニック
- パラメータ最適化手法
- SGD, Momentum, AdaGrad, Adam
- <memo>
- learning_tips: optimizer_compar_native.py
- common optimizer
- パラメータの更新: どのような値を設定するかで学習の成否が分かれる。今回はMNIST データに対する4つの更新手法をテストしました。
- <memo>
- learning_tips: optimizer_compare_mnist.py
- common multi_layer_net

- 重みの初期化
- Xavierの初期化は標準的に使用 sigmoid, tanh は左右対称なのでXavierの初期化、
- ReLuはHeの初期化
- std=0.01, Xavier の初期化, Heの初期化
- <memo>
- learning_tips: weight_init_compare.py
- common multi_layer_net, optimizer

- Xavierの初期化は標準的に使用 sigmoid, tanh は左右対称なのでXavierの初期化、
- ReLuはHeの初期化
- std=0.01, Xavier の初期化, Heの初期化
- <memo>
- learning_tips: weight_init_compare.py
- common multi_layer_net, optimizer

- 過学習を抑制する方法
- Dropout 過学習を抑制する方法 ニューロンをランダムに消去しながら学習する手法。
- 訓練時に隠れ層のニューロンをランダムに選び出し、その選び出したニューロンを消去する。データが流れるたびに消去するニューロンをランダムに選択する。
- テスト時 すべてのニューロンの信号を伝達するが各ニューロンの出力に対して訓練時に消去した割合を乗算して出力
- memo
- common/trainer.py, multi_layer_net_extend.py
- learning_tips/overfit_dropout.py (True - dropout: False - no dropout)
- W/O Dropout

- W/ Dropout

- Weightdecay -過学習を抑制する方法 損失関数に対して重みのL2ノルム(重みの2乗ノルム)を加算する方法 1/2λW**2

畳み込みニューラルネットワークの実装
畳み込みニューラルネットワーク(convolution neural networks: CNN) は画像認識や音声認識などで使用される 。CNNは新たにConvolution レイヤ(畳み込み層)とPoolingレイヤ(プーリング層)が加わる。 3次元データの畳み込み演算は縦・横方向に加えて奥行方向(チャネル方向)に特徴マップが増える
全結合層(Affineレイヤ)では隣接するニューロンが全て連結されており出力の数は任意に聞けることができます。問題点としてはデータの形状が無視され画像の場合 縦 横 チャネル方向の3次元ですが全結合層に入力するときは3次元のデータを平らの1次元のデータにする必要がある。 MINISTデータの場合入力画像(1,28,28) 1チャネル、縦28ピクセル、横28ピクセル ー1列を784個のデータをAffineレイヤに入力
一方畳み込み層(Convolutionレイヤ)は形状を維持する。 入力データを3次元データとして次の層にデータを出力する。 畳み込み層の入出力データを特徴マップ(feature map)という。
畳み込み演算:入力データに対してフィルターを適用 入力データは縦/横方向の形状をもつデータでフィルターも同様に縦/横方向の形状をもつ。フィルターという用語は「カーネル」と表現することもある。
入力(4、4)フィルター(3、3)出力(2、2)
パディング: 入力データの周囲に固定のデータ(たとえば0)を埋めることがある。(4、4)のサイズパディングにより(6、6)になる。 そして(3、3)のフィルタをかけると(4、4)の出力データが生成 #出力サイズは入力サイズの2要素分だけ縮小される。
ストライド フィルターを適用する位置の間隔をストライド(stride)と呼ぶ。
畳み込み演算でも同じようにバッチ処理を行う。 各層を流れるデータは4次元のデータとして格納(batch_num, channel, height, width)
ブーリング層 縦/横方向の空間を小さくする演算 2x2の領域を一つ要素に集約する処理を行い空間のサイズを小さくする。 学習するパラメータはない。 対象領域から最大値(平均値)を取るだけの処理なので学習するパラメータは存在しない。また入力データと出力データのチャネルは変化しない。
Convolution/Pooling の実装
メモ im2col(image to column)入力データに対してフィルターを適用する場所の領域(3次元)を横方向に1列に展開 大きな行列にまとめて計算 common/util.py
im2col(input_data, filter_h, filter_w, stride=1, pad=0)
input_data (データ数、チャネル、高さ、横幅)
filter_h フィルターの高さ
filter_w フィルターの横幅
stride ストライド
pad パディング
Convolution レイヤの初期化
フィルター(重み)、バイアス、ストライド、パディングを引数として受け取る。
フィルターは(FN、C、FH、FW)の4次元 FN/Filter Number, C/Channel, FH/FilterHeight, FW/Filter Width
im2colを展開しフィルターもreshapeを使用し2次元配列に展開
reshape(FN, -1) -1は便利な機能 多次元配列の要素風のつじつまがあうように要素数をまとめる。
forwardの実装
出力サイズを適切な形状にする。 NumPy のtransposeを使用する。transposeは多次元配列の順番を入れ替える関数
class Convolution:
def __init__
def forward
逆伝播の際にはim2col の逆の処理col2im
<memo> common/layer.py
Poolingレイヤの実装
im2colを使い入力データを展開、ブーリングの場合チャネル方向には独立である。チャネルごとに独立して展開する。
Class Pooling
def __init__
def forward
ここまでが初期化で行う処理
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""損失関数を求める
引数のxは入力データ、tは教師ラベル
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
全結合層(Affineレイヤ)では隣接するニューロンが全て連結されており出力の数は任意に聞けることができます。問題点としてはデータの形状が無視され画像の場合 縦 横 チャネル方向の3次元ですが全結合層に入力するときは3次元のデータを平らの1次元のデータにする必要がある。 MINISTデータの場合入力画像(1,28,28) 1チャネル、縦28ピクセル、横28ピクセル ー1列を784個のデータをAffineレイヤに入力
一方畳み込み層(Convolutionレイヤ)は形状を維持する。 入力データを3次元データとして次の層にデータを出力する。 畳み込み層の入出力データを特徴マップ(feature map)という。
畳み込み演算:入力データに対してフィルターを適用 入力データは縦/横方向の形状をもつデータでフィルターも同様に縦/横方向の形状をもつ。フィルターという用語は「カーネル」と表現することもある。
入力(4、4)フィルター(3、3)出力(2、2)
パディング: 入力データの周囲に固定のデータ(たとえば0)を埋めることがある。(4、4)のサイズパディングにより(6、6)になる。 そして(3、3)のフィルタをかけると(4、4)の出力データが生成 #出力サイズは入力サイズの2要素分だけ縮小される。
ストライド フィルターを適用する位置の間隔をストライド(stride)と呼ぶ。
畳み込み演算でも同じようにバッチ処理を行う。 各層を流れるデータは4次元のデータとして格納(batch_num, channel, height, width)
ブーリング層 縦/横方向の空間を小さくする演算 2x2の領域を一つ要素に集約する処理を行い空間のサイズを小さくする。 学習するパラメータはない。 対象領域から最大値(平均値)を取るだけの処理なので学習するパラメータは存在しない。また入力データと出力データのチャネルは変化しない。
Convolution/Pooling の実装
メモ im2col(image to column)入力データに対してフィルターを適用する場所の領域(3次元)を横方向に1列に展開 大きな行列にまとめて計算 common/util.py
im2col(input_data, filter_h, filter_w, stride=1, pad=0)
input_data (データ数、チャネル、高さ、横幅)
filter_h フィルターの高さ
filter_w フィルターの横幅
stride ストライド
pad パディング
Convolution レイヤの初期化
フィルター(重み)、バイアス、ストライド、パディングを引数として受け取る。
フィルターは(FN、C、FH、FW)の4次元 FN/Filter Number, C/Channel, FH/FilterHeight, FW/Filter Width
im2colを展開しフィルターもreshapeを使用し2次元配列に展開
reshape(FN, -1) -1は便利な機能 多次元配列の要素風のつじつまがあうように要素数をまとめる。
forwardの実装
出力サイズを適切な形状にする。 NumPy のtransposeを使用する。transposeは多次元配列の順番を入れ替える関数
class Convolution:
def __init__
def forward
逆伝播の際にはim2col の逆の処理col2im
<memo> common/layer.py
Poolingレイヤの実装
im2colを使い入力データを展開、ブーリングの場合チャネル方向には独立である。チャネルごとに独立して展開する。
Class Pooling
def __init__
def forward
- 入力データを展開
- 行ごとに最大値を求める
- 適切な出力サイズにする
CNNの実装
構成 [Convolution-ReLU-Pooling-Affine-ReLU-Affine-Softmax]
<memo>
cnn/train_convnet.py, simple_convenet.py
simple_convnet.py
cnn/train_convnet.py, simple_convenet.py
simple_convnet.py
SimpleConvNet の初期化
class SimpleConvNet:
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) /
filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2
(conv_output_size/2))
ハイパーパラメータをディクショナリから取りだし、畳み込みの出力サイズを計算
続いて重みパラメータの初期化 (1層目 畳み込み(W1,b1)、残り全結合層の重みとバイアス(W2,b2) (W3, b3)) 必要なレイヤを生成 先頭から順序つき(OrderDict)のレイヤーに追加 最後のSoftmaxWithLoss はlastLayer に追加
# 重みの初期化
self.params = {}
self.params['W1'] = weight_init_std * \np.random.randn(filter_num, input_dim[0],filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# レイヤの生成
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
class SimpleConvNet:
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) /
filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2
(conv_output_size/2))
ハイパーパラメータをディクショナリから取りだし、畳み込みの出力サイズを計算
続いて重みパラメータの初期化 (1層目 畳み込み(W1,b1)、残り全結合層の重みとバイアス(W2,b2) (W3, b3)) 必要なレイヤを生成 先頭から順序つき(OrderDict)のレイヤーに追加 最後のSoftmaxWithLoss はlastLayer に追加
# 重みの初期化
self.params = {}
self.params['W1'] = weight_init_std * \np.random.randn(filter_num, input_dim[0],filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# レイヤの生成
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
ここまでが初期化で行う処理
推論、損失関数
初期化後は推論(predict)メソッドと損失関数(loss) メソッドを実装
x は入力データ、tは教師ラベル
推論: 追加したレイヤを先頭から呼出し次のレイヤに渡す。
損失関数: 推論のforward処理に加え、最後の層SoftmaxWithLossレイヤまでforward処理を行う。
x は入力データ、tは教師ラベル
推論: 追加したレイヤを先頭から呼出し次のレイヤに渡す。
損失関数: 推論のforward処理に加え、最後の層SoftmaxWithLossレイヤまでforward処理を行う。
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""損失関数を求める
引数のxは入力データ、tは教師ラベル
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
誤差伝播法
def gradient(self, x, t):
"""勾配を求める(誤差逆伝搬法)
Parameters
----------
x : 入力データ
t : 教師ラベル
Returns
-------
各層の勾配を持ったディクショナリ変数
grads['W1']、grads['W2']、...は各層の重み
grads['b1']、grads['b2']、...は各層のバイアス
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 設定
grads = {}
grads['W1'],grads['b1']=self.layers['Conv1'].dW,self.layers['Conv1'].db
grads['W2'],grads['b2']=self.layers['Affine1'].dW,self.layers['Affine1'].db
grads['W3'],grads['b3']=self.layers['Affine2'].dW,self.layers['Affine2'].db
return grads
train_convnet.py
import sys, os
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from simple_convnet import SimpleConvNet
from common.trainer import Trainer
# データの読み込み
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
max_epochs = 20
network = SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
訓練データとテストデータ
=============== Final Test Accuracy ===============
test acc:0.9903

def gradient(self, x, t):
"""勾配を求める(誤差逆伝搬法)
Parameters
----------
x : 入力データ
t : 教師ラベル
Returns
-------
各層の勾配を持ったディクショナリ変数
grads['W1']、grads['W2']、...は各層の重み
grads['b1']、grads['b2']、...は各層のバイアス
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 設定
grads = {}
grads['W1'],grads['b1']=self.layers['Conv1'].dW,self.layers['Conv1'].db
grads['W2'],grads['b2']=self.layers['Affine1'].dW,self.layers['Affine1'].db
grads['W3'],grads['b3']=self.layers['Affine2'].dW,self.layers['Affine2'].db
return grads
train_convnet.py
import sys, os
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from simple_convnet import SimpleConvNet
from common.trainer import Trainer
# データの読み込み
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
max_epochs = 20
network = SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
訓練データとテストデータ
=============== Final Test Accuracy ===============
test acc:0.9903

ディープラーニング(VGG参考)
VGGは畳み込み層とブーリング層から構成されるCNN
全部で16層(VGG16) 19層(VGG19)と呼ぶ場合がある。
3x3の小さなフィルターによる畳み込み層を連続して行う。
畳み込み層を連続しプーリング層でサイズを半分にする処理を行う。
全結合結合層を経由
3x3の小さなフィルターによる畳み込み層
層が深くなるにつれチャネル数大きく(16,16,32,32,64,64)なる。
活性化関数はReLU
プーリング層を挿入し中間データの空間サイズを徐々に小さく
最後に全結合層の後にDropoutレイヤを使用
Adamによる最適化
重みの初期値[He]を使用

<memo>
cnn/train_deepnet.py, deep_convnet.py
deep_convnet.py
ネットワーク構成は下記の通り
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
affine - relu - dropout - affine - dropout - softmax
deep_ConvNet の初期化
def __init__(self, input_dim=(1, 28, 28),
# レイヤの生成===========
def loss(self, x, t):
# backward
tmp_layers = self.layers.copy()
dout = layer.backward(dout)
conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},
conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
hidden_size=50, output_size=10):
畳み込み層を連続しプーリング層でサイズを半分にする処理を行う。
全結合結合層を経由
3x3の小さなフィルターによる畳み込み層
層が深くなるにつれチャネル数大きく(16,16,32,32,64,64)なる。
活性化関数はReLU
プーリング層を挿入し中間データの空間サイズを徐々に小さく
最後に全結合層の後にDropoutレイヤを使用
Adamによる最適化
重みの初期値[He]を使用
<memo>
cnn/train_deepnet.py, deep_convnet.py
deep_convnet.py
ネットワーク構成は下記の通り
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
affine - relu - dropout - affine - dropout - softmax
deep_ConvNet の初期化
def __init__(self, input_dim=(1, 28, 28),
# レイヤの生成===========
def loss(self, x, t):
# backward
tmp_layers = self.layers.copy()
dout = layer.backward(dout)
conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},
conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
hidden_size=50, output_size=10):
self.layers = []
self.layers.append(Convolution(self.params['W1'], self.params['b1'],
conv_param_1['stride'], conv_param_1['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W2'], self.params['b2'],
conv_param_2['stride'], conv_param_2['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W3'], self.params['b3'],
conv_param_3['stride'], conv_param_3['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W4'], self.params['b4'],
conv_param_4['stride'], conv_param_4['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W5'], self.params['b5'],
conv_param_5['stride'], conv_param_5['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W6'], self.params['b6'],
conv_param_6['stride'], conv_param_6['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Affine(self.params['W7'], self.params['b7']))
self.layers.append(Relu())
self.layers.append(Dropout(0.5))
self.layers.append(Affine(self.params['W8'], self.params['b8']))
self.layers.append(Dropout(0.5))
self.last_layer = SoftmaxWithLoss()
推論、損失関数
def predict(self, x, train_flg=False):for layer in self.layers:
if isinstance(layer, Dropout):
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
y = self.predict(x, train_flg=True)
誤差伝播法
def gradient(self, x, t):dout = 1
tmp_layers.reverse()
return self.last_layer.forward(y, t)
# forward
self.loss(x, t)
dout = self.last_layer.backward(dout)
for layer in tmp_layers:
train_deepnet.py
import sys, os
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
network = DeepConvNet()
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from deep_convnet import DeepConvNet
from common.trainer import Trainer
trainer = Trainer(network, x_train, t_train, x_test, t_test, epochs=20, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr':0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
=============== Final Test Accuracy ===============
test acc:0.9936
誤認識した例
<memo>
CNN/misclassified_mnist.py
test accuracy:0.9935
======= misclassified result =======
{view index: (label<正解>, inference<推論の結果>), ...}
{1: (6, 0), 2: (3, 5), 3: (3, 5), 4: (8, 3), 5: (7, 3), 6: (1, 3), 7: (8, 9), 8: (6, 0), 9: (6, 5), 10: (7, 2), 11: (9, 4), 12: (7, 1), 13: (5, 3), 14: (1, 3), 15: (0, 6), 16: (9, 4), 17: (7, 9), 18: (6, 0), 19: (9, 8), 20: (4, 9)}

演算精度の削減
深層学習では数値精度をそこまで必要としない。半制度浮動小数点(half float)でも問題なく学習できる。
<memo>
CNN/half_float_network.py

コメント
コメントを投稿